Basic Concepts » History » Revision 32
« Previous |
Revision 32/44
(diff)
| Next »
Taya Sergeeva, 03/28/2013 12:24 PM
Basic Concepts of Reconfigurable Test Program Generation¶
By Alexander Kamkin
- Table of contents
- Basic Concepts of Reconfigurable Test Program Generation
Introduction¶
Nowadays, a large number of microprocessor devices are designed and produced all round the world. Many of them are based on standard instruction set architectures (ISA), but there are also designs with the unique instruction sets and designs that significantly extend the existing standards. A frequently used approach to verify such kind of microprocessors is to develop testing tools from scratch without using the components developed previously. However, it does not work in the modern economy with the ever-shrinking time to market and the exponential growth in hardware complexity.
It is well known that test program generation (TPG) is the central means for verifying microprocessors and other programmable devices at the core or full-chip level. A test program is a valid sequence of instructions that solves a specific verification task (in other words, creates a certain set of interactions within the target design and, possibly, checks the correctness of the design''s state at the end of execution). A tool that creates test programs for a given microprocessor architecture in an automated way is referred to as a generator or TPG tool.
Here, we describe a concept of a reconfigurable test program generator MicroTESK, which has a platform-independent generation core and is configured by modeling the target ISA and basic microarchitectural features. The idea is not new and has already been implemented in the industrial TPG tools such as Genesys-Pro (IBM Research Lab) and RAVEN (Obsidian Software/ARM). However, tuning the generators for concrete architectures (or even microarchitectures) is still a difficult task that is carried out by special staff only (namely, modeling engineers).
Our goal is to reach a new level in the TPG configuration flexibility. In order to do it, we suggest applying so-called architecture description languages (ADL), which are commonly used for developing microprocessor simulators. In the approach suggested, a microprocessor ISA is described in some ADL and then automatically translated into a microprocessor model together with a test coverage model. Fine tuning of the generator is performed by the subsystem-specific configuration files. Such an approach is especially useful in the early design stages when the project is frequently modified and rapid generator reconfiguration is required.
Reconfigurable Test Program Generation¶
The key idea of the reconfigurable TPG is that configuration of a generator for a concrete microprocessor architecture is implemented as easy as possible. It is obvious that to fulfill this requirement, a generator should be divided into two parts: (1) a platform-independent component (so-called core or engine) and (2) a component describing all platform-specific features (model or configuration). Such kinds of TPG tools are usually called model-based test program generators. This is the first and probably the most important step the generators have made during their evolution. Let us consider the model-based approach a bit more in detail using Genesys-Pro as an example (see Fig. 1).
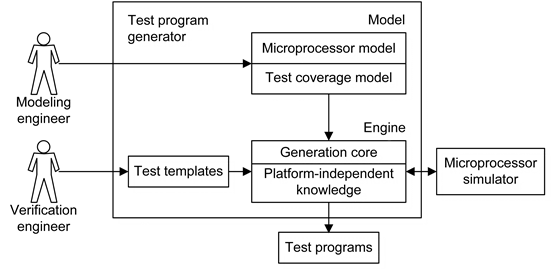
Figure 1. General structure of a model-based test program generator
A verification engineer provides a test template of the scenario that should occur in the test program. A TPG tool generates a program by formulating and then solving constraints for each instruction of the test template or for groups of instructions. It also randomizes values of the unspecified parameters to produce different test program variations for the template given. The constraints are formulated in terms of the model, which consists of the microprocessor model and test coverage model. The first of them defines syntax and semantics of the target design''s instructions, while the second one describes special conditions (known as test situations) to be achieved when verifying the design.
After formulating the CSP, the generation core solves it by using external or built-in solvers and assigns the values to the instructions'' operands. Then, it interprets the instructions under processing (for example, by using a microprocessor simulator) and takes the next group of instructions. Having performance limitations, TPG tools generally do not process test templates as a whole. Instead, they split them up into small pieces and formulate several CSPs. It is clear that such a technique can fail to find an exact solution of the joint CSP even when one is available, but it works well for test programs with low-density dependencies between instructions.
Coming back to the topic, what is the main distinction of the reconfigurable TPG from the conventional model-based TPG? Tuning of a generator (in other words, creation of a microprocessor model together with a test coverage model) should be as much flexible and automated as it can be done by an ordinary verification engineer, not only by a trained modeling specialist. The important technological requirement for reconfigurable tools is usage of well-known or easy-to-learn languages, for example, ADLs (nML, ISDL, EXPRESSION, etc.) to represent a model. One of the possible solutions is implemented in a research prototype MA 2 TG (National University of Defense Technology, China).
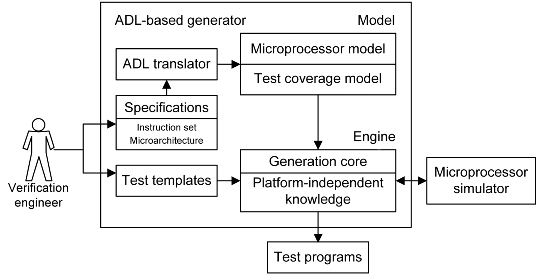
Figure 2. General structure of an ADL-based test program generator
The main contributions of the scheme (see Fig. 2) are as follows. First, it eases microprocessor modeling by using ADL specifications. Second, it automates test coverage extraction via static analysis of the ADL code. Third, it allows constructing a microprocessor simulator automatically. Being rather flexible, the ADL-based approach is however not exactly what we mean by reconfigurable. Specification of microarchitecture by means of ADLs is rather awkward. There is often no need to create a microarchitectural description (especially a structure-oriented one). All information the generator should know can be expressed with a high-level configuration of microprocessor subsystems.
A good example is a cache memory. As structural description of a typical cache unit consists of several thousand lines of code (LOC), its configuration can be set by five parameters only: (1) size, (2) associativity, (3) an index calculation function, (4) a tag calculation function, and (5) policy of data displacement. Moreover, if we are speaking about data displacement, only a few strategies are in general use (LRU, pseudo LRU, and some others). Thus, it is possible to create a library of typical configurations and choose an appropriate one when tuning the generator. So, the idea is to describe microarchitectural properties using subsystem-specific parameters. This concept is illustrated in Fig. 3.
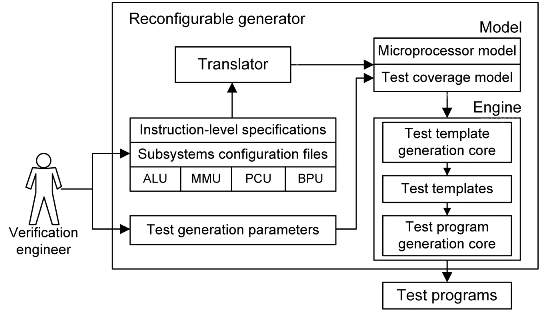
Figure 3. General structure of a reconfigurable test program generator
Another problem being solved by the reconfigurable TPG is automated test template generation (of course, the possibility to develop templates manually remains as before). There is an evident dilemma here. To be able to generate test templates providing high-quality verification, accurate models are needed, but their creation is labor-consuming and thereby contradicts the concept of easy configuration. The dilemma is usually solved as follows. In early design stages, simple models coupled with the light-weight test generation techniques are used. As soon as the project becomes more mature, one can apply more accurate models and more directed tests.
Concluding the section, let us outline the basic requirements for the reconfigurable TPG. First, there should be a possibility to quickly change the microprocessor instruction set (add new instructions, modify the existing ones, and so on). Second, a user should be able to easily change the microarchitectural properties of the design (cache parameters, address translation algorithm, etc.). Third, a reconfigurable TPG tool should implements facilities for adding new test situations for single instructions and for groups of instructions. Finally, it should be able to generate test programs automatically according to high-level parameters. These problems have not been solved by the existing tools, and they are the main subject of our work.
Configuration of Microprocessor Subsystems¶
In this section, we consider the suggested method for developing reconfigurable test program generators. A target design''s architecture is described in one of the supported ADLs (the present version of the tool supports only nML/Sim-nML; the list of the supported languages will be extended in the future). A microprocessor description focuses on general functionality of the instructions not considering the design''s microarchitecture. Sim-nML code specifying the integer addition instruction (ADD) from the MIPS ISA is shown below.
op ADD(rd: GPR, rs: GPR, rt: GPR)
action = {
if(NotWordValue(rs) || NotWordValue(rt))
then
UNPREDICTABLE();
endif;
tmp_word = rs<31..31>::rs<31..0> + rs<31..31>::rt<31..0>;
if(tmp_word<32..32> != tmp_word<31..31>)
then
SignalException("IntegerOverflow");
else
rd = sign_extend(tmp_word<31..0>);
endif;
}
syntax = format("add %s, %s, %s", rd.syntax, rs.syntax, rt.syntax)
op ALU = ADD | SUB | ...
}
This description is rather compact and almost replicates the instruction''s specification in the MIPS manual. Several particular features should be emphasized. First, ADL specifications can use predefined functions, like UNPREDICTABLE, which indicates the situations, where the design''s behavior is undefined (such situations should not be created in test programs). Second, by analyzing control flow one can automatically extract test coverage models for individual instructions. In the example above, there are two basic situations for the ADD instruction:
IntegerOverflow:
...
tmp_word = rs<31..31>::rs<31..0> + rs<31..31>::rt<31..0>;
ASSERT(tmp_word<32..32> != tmp_word<31..31>);
Default:
...
tmp_word = rs<31..31>::rs<31..0> + rs<31..31>::rt<31..0>;
ASSERT(tmp_word<32..32> == tmp_word<31..31>);
Third, it is possible to examine potential dependencies via registers by determining which of the instructions use the registers of the same type. Fourth, instructions can be grouped into hierarchical classes providing a generator and a verification engineer with useful information to be utilized within test templates. Finally, basing on such specifications, a generator is able to predict the correct result of the test program execution. From the practical point of view, the things stated above mean that as soon as the microprocessor ISA is specified, without any additional development one can use test templates of the following kind (of course, they can be complicated by using the sequencing-control statements):
ALU ?, ?, ?
ADD R, ?, ? @ Default
SUB ?, R, ? @ IntegerOverflow
The first line of the template produces any instruction from the ALU class (ADD, SUB, MUL, DIV or some other). Since the test situation for the instruction is unspecified, it might be any valid situation. The second line produces an ADD instruction being executed normally. The third one produces a SUB instruction causing the integer overflow exception. There is also a register dependency between the second ADD and the third SUB. In spite of shallow nature of the behavioral specifications, they might however be useful. There are three types of tests that can be generated fully automatically:
- tests for single instructions (covering all test situations for all instructions);
- combinatorial tests (enumerating short sequences of instructions, test situations for them and dependencies between them);
- random tests (producing random but valid sequences of instructions).
These facilities suffice for many verification tasks. If more directed test programs are needed, one should provide an additional description of the microprocessor subsystems. To configure the generator, we suggest using subsystem-specific languages instead of the universal structure-oriented ADLs. It significantly eases the generator tuning and simplifies analysis of specifications.
Memory Management Unit¶
Configuration of a memory management unit (MMU) touches upon such devices as a cache memory (L1 and L2), translation lookaside buffer (TLB), main memory and, probably, some others. The main goal of the MMU configuration is to enable the generator to process memory-related events and complex data dependencies in test templates. These events include buffers hits/misses and memory exceptions. The data dependencies take into account structural properties of the memory devices, for example, there can be such dependencies as hit into the same cache set or the like.
A typical memory buffer (cache or TLB) is modeled as an array consisting of sets of lines, where a line can be a structure comprising several bit vectors, so-called fields. For example, a TLB entry of a MIPS microprocessor consists of the following fields: R, VPN2, MASK, G, ASID, PFN0, V0, C0, D0, PFN1, V1, C1 and D1. A fully-associative device contains a single set of lines; a direct-mapped one is an array of single-line sets. Each device stores some data which can be accessed (read from or written into) by their address. If a device contains a line with a given address, this situation is called a hit; the opposite situation is refered to as a miss. If a miss occurs, the device usually displaces one of the set''s lines with the line associated with the address given.
All memory devices are configured with the following set of parameters: associativity (associativity, i.e. set size), sets (number of sets), line (optional description of a line''s fields), index (function for index calculation), match (predicate checking whether a line and an address match each other) and policy (data displacement strategy). Here is an example:
buffer L1 {
associativity = 4;
sets = 128;
line = (tag:30, data:256);
index(addr:PA) = addr<9..8>;
match(addr:PA) = line.tag == addr<39..10>;
policy = lru;
}
The configuration above describes a 4-way set associative buffer (see the parameter sets) consisting of 128 sets (lines). Each line of the cache contains a 30-bit tag and 256-bit data (line). When accessing data, the cache determines a set by calculating a 2-bit index (index). If a miss occurs, i.e. the set does not contain a line with the tag equal to the 30 upper bits of the physical address (match), the cache displaces the least-recently-used (LRU) line of the set (policy).
When all the memory devices are configured, the general memory access algorithms should be defined. Let us consider the MIPS''s instruction LD, which loads a 64-bit double word from the main memory into the general-purpose register (GPR). Its Sim-nML specification written according to the ISA manual looks as follows:
vAddr := sign_extend(offset) + base;
if(vAddr<2..0> != 0)
then
SignalException("AddressError");
endif
pAddr::CCA := AddressTranslation(vAddr, DATA, LOAD);
memdoubleword := LoadMemory(CCA, DWORD, pAddr, vAddr, DATA);
rt := memdoubleword;
If the virtual address vAddr is unaligned, then the address error exception is raised. Otherwise, the virtual address is translated into the physical one (pAddr), and cache coherence algorithm (CCA) is get. After that, a 64-bit double word (memdoubleword) is loaded from the main memory and then written into the general-purpose register rt. Translation of a virtual address is modeled as the invocation of the AddressTranslation function. Reading from the main memory is described with the help of the LoadMemory function.
In terms of the example, we need to concretize these two functions. Special operators are proposed for this purpose:
hit<Buffer>(Address) {[loaded:Data1[;]][storing:Data2]}
states that an instruction accessesBufferusingAddress, and a hit occurs;Data1are data loaded from the corresponding line of the device (read operation), andData2are data to be stored in the line (write operation);miss<Buffer>(Address){[replacing:Data]}$using
states that an instruction accesses @BufferAddressand a miss occurs;Dataare data that replace the data stored in the corresponding line of the device.
Analysing the specifications of the memory access algorithms, the generator automatically constructs the set of memory-related test situations. A bit simplified fragment of the MIPS address translation specification corresponding to a TLB hit and a L1 hit is given below:
vAddr := sign_extend(offset) + base;
if(hit<TLB>(vAddr){loaded:PFN})
then
pAddr := PFN::vAddr<12..0>;
if(hit<L1>(pAddr){loaded:memdoubleword})
then
rt := memdoubleword;
...
endif
...
endif
Here is an example demonstrating the basic facilities of the TPG tool on specifying memory-related test situations in test templates (SD is an instruction that stores a 64-bit double word into the main memory).
LD ?, ?(?) @ hit<TLB>{loaded:PFN1} && miss<L1> && hit<L2>
...
SD ?, ?(?) @ hit<TLB>{loaded:PFN2} && PFN1 = PFN2 && hit<L1>
Pipeline Control Unit¶
Configuration of a pipeline control unit (PCU) is targeted at automated generation of test templates covering pipeline hazards including exceptions, data hazards, structural hazards and control hazards. The latter are described more in detail in the next section. Configuration describes a static structure of the microprocessor pipeline as well as its dynamic behavior. Description of the classical 5-stages RISC pipeline looks as follows.
pipeline() {
IF(I); // Fetch
ID(I); // Decode
EX(I); // Execute
MEM(I); // Memory access
WR(I); // Writeback
}
It starts with the scope pipeline that contains top-level units (so-called, pipe stages) participating in the instruction processing. Each unit takes a single input/output parameter, which is an instruction being processed. It should be said that a unit may include nested subunits and use the usual conditional statements (if, switch, while, etc.) to describe the pipeline control flow. A simplified example is given below.
EX(I: Instruction) {
switch(I.type) {
case ALU: EX_ALU(I);
case FPU: EX_FPU(I);
...
}}
}
Two items should be mentioned here. First, each unit can specify a set of exceptions it may raise (nested units are allowed to extend the set by specific exceptions). Second, each calling sequence should contain at least one operator DELAY used to specify how many cycles a certain operation (or microoperation) takes. Here is an example illustrating the above mentioned things.
FPU(I: Instruction) throws
Inexact, Overflow, Underflow {
DELAY(10..15);
}
Exceptions and delays provides the TPG tool with information that can be used for automated generation of test templates aimed at covering simultaneous exceptions (i.e. exceptions being raised at the same cycle or close to each other) and structural hazards (i.e. situations when two or more instructions tries to access the same unit of the microprocessor). When analysing the pipeline configuration, the generator extracts the basic templates covering all single hazards. Such templates are usually very simple ones; for example, a basic template for the structural hazard via the floating point unit (FPU) looks as follows.
$PreInstructions
FPU ?, ?, ? // The first FPU access
$InnerInstructions
FPU ?, ?, ? // The second FPU access
$PostInstructions
As soon as the basic templates are extracted, it is possible to generate tests programs covering all the single hazards. The generator creates all possible combinations of the conflicting instructions randomizing their environment (in the example above, $PreInstructions, $InnerInstructions and $PostInstructions). The main restriction here is that an environment should not cancel the target hazard (for example, it should not access the unit shared by the conflicting instructions).
A more advanced technique for test program generation uses composition of the basic templates. There are several types of composition operators including overlapping (T1 || T2), shift (T1 >> T2), nesting (T1[T2]) and concatenation (T1 . T2). The generator applies these operators to the basic templates constructing various syntactical structures. The approach allows testing rather complex situations in the microprocessor behavior. Application of the composition operators to basic templates is shown in the example below (T1[T2 >> T3] . T4).
// Template T1 (Memory Dependency)
LD ?, ?(?) @ hit<TLB>{loaded:PFN1}
// Template T2 (Register Dependency)
ADD R, ?, ?
// Template T3 (Structural Hazard)
DIV.S ?, ?, ?
SUB ?, R, ?
DIV.D ?, ?, ?
SD ?, ?(?) @ hit<TLB>{loaded:PFN2} && PFN1 = PFN2
// Template T4 (Exception)
FPU ?, ?, ? @ Overflow
Branch Processing Unit¶
ADL-based instruction set specifications provide enough information for generating branching programs not getting caught in an endless loop. TPG is performed by enumeration (or random construction) of various control flow graphs (CFG) and different execution traces for those graphs. Enumerating execution traces for a given CFG is based on the bounded depth-first exploration of the branch execution tree. To guarantee a test to be executed according to a trace given, auxiliary instructions (so-called control instructions) are automatically inserted into the test program. Those instructions change the registers used by the branch instructions so as to fulfill the conditions specified in the trace.
The template below contains a branch instruction BEQ (branch if equal) which is executed two times (when it is executed for the first time, the branch condition is true; then, the condition becomes false, and test execution is finished). The control instruction (ADDI) increments one of the registers used by the branch instruction (the initial values of the registers are equal).
INIT:
ORI R1, R0, 2011
ORI R2, R0, 2011 // R1 = R2
...
J START
NOP
...
BACK:
ADDI R1, R1, 1 // Control Instruction
FPU ?, ?, ?
START:
BEQ R1, R2, BACK @ trace = {true, false}
LD ?, ?(?)
STOP:
Speaking about configuration of a branch processing unit (BPU), we recognize two levels (namely, simple configuration and advanced configuration). The first of them is simply setting a number of branch delay slots (i.e. instructions located immediately after a branch instruction, which are executed even if the preceding branch is taken). Sometimes, this information can be derived from the specifications, but sometimes it is absent. Advanced configuration describes more sophisticated mechanisms, like branch prediction.
Based on the paper Alexander Kamkin, Eugene Kornykhin and Dmitry Vorobyev. "Reconfigurable Model-Based Test Program Generator for Microprocessors", A-MOST 2011.
Updated by Taya Sergeeva about 12 years ago · 44 revisions