Multimodule strategies » History » Revision 5
« Previous |
Revision 5/6
(diff)
| Next »
Alexey Polushkin, 07/12/2016 06:38 PM
Multimodule strategies¶
Preface¶
Module division strategies allow to verify dependent Linux kernel modules together to analyze their source code including export functions, since during verification of a single module its exported functions are ignored and are not analyzed with an any used verification tool. Below you can find an explanation and corresponding configuration properties of already implemented referred strategies. All mentioned below strategies configuration properties should be specified by a user in JSON file.
Choose a strategy and its parameters carefully, since groups of a big size require much time and memory to complete a verification. At the same time several strategies generate too many groups for modules with many dependencies which also require much time for verification of all them.
Strategy parameters should be described in the "LKVOG strategy" property in the configuration file of a job. User files should be described in the "Linux kernel" property of configuration file of a job.
Separate modules¶
Parameters:
None
The strategy generates groups with a single unique module per group. This is a strategy used by default by Core component of a Klever verification system.
Closure¶
Parameters:
cluster size : int - Max size of a generated group of modules to be checked together. Given value should be a non-zero integer number.
According to this strategy a transitive closure of modules for a given module is collected and divided into groups of specified size provided as “cluster size” parameter. The division is performed with a heuristic algorithm based on BFS.
Note, that this simple strategy is useful to verify as much modules as possible for a given one, but for modules with a significant number of modules in dependencies and with a small provided group size parameter the strategy may generate too many groups. Better to use an another strategy in the case.
Scotch¶
Parameters:
cluster size: int — Max size of a generated group of modules to be checked together. Given value should be a non-zero integer number.
balance tolerance: float — Expected a float number be between 0.0 and 1.0. This is an optional parameter (a default value is 0.05). Value increase leads to increment of a number of generated groups but average size of groups will be greater and connectivity inside a group will be lower.
scotch path: string — Absolute path to a directory with installed Scotch gpart tool (for example “/my/path/Scotch dir/bin/”). The Scotch tool is available there.
A main idea of the strategy is to collect all dependencies between all modules in the provided Kernel and solve k-balanced graph partitioning problem trying to extract connected groups of modules of a provided size cutting as less dependencies as possible.
The main advantage of a strategy is a predictable number of groups to be generated. You can calculate it using the formula below: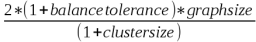
The main drawback of the strategy is an unpredictable choice of modules for a group. For example it can select groups from different subsystems and put modules which are in dependencies of a module in which you are interested in to an another group.
Advanced¶
Parameters:
cluster size: int — Max size of a generated group of modules to be checked together. Given value should be a non-zero integer number. This is an optional parameter (default value is 5).
division type: string — The type of strategy. Value can be one chosen from the following list: «Library», «Module», «All». «Library» value means appending to a group only that modules which call export functions from modules of a group. «Module» value means appending to a group only that modules which provide export function to the group under consideration. «All» value means mixed «Library» and “Module”. This is an optional parameter (the default value is «All»).
analyze all export function: bool — If the value is True then for an every export function in a module a group is generated that contains a module that calls the export function. This is an optional parameter (the default value is True if division type is not equal to «Module» value and is False otherwise)
analyze all calls: bool — If the value is “True” then for an every export function called in a module will be generated at least one group containing the module that provides the export function. This is an optional parameter (the default value is True if division type is not equal to «Library» and is False otherwise)
priority on module size: bool — If the value is “True” then the strategy takes into consideration sizes of modules. This is an optional parameter (the default value is “True” if module sizes are given and is False otherwise)
priority on export function: bool — If the value equals to ''True'' then the strategy takes into consideration the count of export functions provided by a module. This is an optional parameter (the default value is True if division type is not equal to «Module» and is False otherwise)
priority on calls: bool — If the value is set as ''True'' then the strategy takes into consideration the count of export functions called from a module. This is an optional parameter (the default value is equals to True if division type is set as not «Library» and is False otherwise)
maximize subsystems: bool — If the value is ''True'' the strategy takes into consideration a subsystem of a module. This is an optional parameter with the default value ''True''.
max group for module: int — The maximum number of groups containing a module. In fact the number of such groups can be more because of analysis of all export functions and analysis of all calls, since groups are chosen independently for each module under consideration. Given value should be a non-zero integer number. This is an optional parameter with the default value equals to 5.
minimize groups for module: bool — If the configuration property is set as ''True'' and if analysis of all export function or analysis of all calls is set as True then the strategy stops generating groups when all export functions have been called or export function is present. This is an optional parameter with the default value equals to ''True''.
user deps: object — {«Module1»: [«Module11», …, «Module1N»], …, «ModuleK»: [«ModuleK1», …, «ModuleKM»]}. A group that contains a module given as a key of a json object key will also contain all modules given as values in the list value of the key it does not contradict with a set maximum cluster size parameter. This is an optional parameter with an empty json object.
The strategy gradually fills a group of modules using greedy algorithm taking into account various properties of modules like their size, particular exporting or importing functions, subsystem and etc.. First, the strategy creates a group, that contains the only single given module. Then for every module that calls or provides export functions to modules from a referred group, it assigns a numerical vector which reflects properties mentioned above. Then for each element in the vector the strategy filters out modules which vector element is less than twice a maximum value. Consequently it sorts vectors and appends a module with the largest vector estimation. It repeats until the group reaches maximum size.
Manual¶
Parameters:
groups: object - {«Module1»: «Module111», …, «Module11N»], …, [«Module1K1», …, «Module1KN», …, «ModuleP»: [[…, «ModuleKP1», …, «ModuleKPM»]]}. Groups for a module given as a key of a json object key will consist groups given as values in the list value of the key.
For every module given as a key of the “groups” parameter the strategy generates groups listed in the corresponding value of parameter. Each group must be specified in the load order and must contain module given as a key. If module does not present in the key of the “groups” parameter, then the strategy generates one group that contains the single module.
When you going to verify a module together with a kernel library module (for example lib/nlattr.o), you should specify the kernel library module ending in .o
User files¶
If you are going to use a strategy, that differs from “Separate modules” strategy, all modules in the Linux kernel will be built to extract dependencies. It takes a lot of time, since it requires to prebuild the kernel until verification can be started. If you have a finished run or already built kernel you can pass the file that contains dependencies between modules as an input file for Klever to skip this stage. Also, the strategy “Advanced” collects module sizes and you can pass a file that contains them.
module dependencies file: string — Absolute path to a file that contains module dependencies. Each line of the file contains following: module_A needs «export_function» from module_B. To get the file just do the following steps:
- Configure kernel:
make allmodconfig - Build modules:
make - Install modules:
make INSTALL_MOD_PATH=$PATH_TO_INSTALL modules_install - If you have external modules, also install their:
make INSTALL_MODUL_PATH=$PATH_TO_INSTALL M=ext-modules modules_install - Get the file:
/sbin/depmod -b $PATH_TO_INSTALL $LINUX_KERNEL_VERSION -v > $OUTPUT_FILE
Note
$PATH_TO_INSTALL — path to dir, where will be installed modules
$LINUX_KERNEL_VERSION — version of linux kernel.
$OUTPUT_FILE — the result file
module sizes file: string — Absolute path to a file that contains modules sizes. The format of the file is JSON:{ «moduleA»: size_in_bytesA, …, «moduleZ»: size_in_bytesZ}
Updated by Alexey Polushkin almost 9 years ago · 6 revisions